In the past, running Storm on Windows has been a challenge. While possible, it often involved hacking Storm’s source, hunting down (or building from source) native dependencies, and mucking around with various ways to trick Windows into thinking it’s like UNIX/POSIX.
That alienated a large number of potential adopters who stand to gain from integrating Storm into their big data strategy.
Thanks in large part to contributions from Storm committer David Lao, as well as contributions from Yahoo!, the next release of Storm (0.9.1-incubating) will make life much easier for users who want or need to deploy Storm in an environment where Windows is necessary.
Below I’ve listed the steps necessary to get storm up and running with a sample topology on Windows. It walks through the process of creating a single-node cluster (pseudo-cluster) and deploying a sample “Word Count” topology.
Install Java
Download and install a JDK (Storm works with both Oracle and OpenJDK 6/7). For this setup I used JDK 7 from Oracle.
I installed Java in:
C:\Java\jdk1.7.0_45\
Install Python
To test the installation, we’ll be deploying the “word count” sample from the storm-starter project which uses a multi-lang bolt written in python. I used python 2.7.6 which can be downloaded here.
I installed python in:
C:\Python27\
Install and Run Zookeeper
Download Apache Zookeeper 3.3.6 and extract it. Configure and run Zookeeper with the following commands:
> cd zookeeper-3.3.6
> copy conf\zoo_sample.cfg conf\zoo.cfg
> .\bin\zkServer.cmd
Install Storm
The changes that allow Storm to run seamlessly on Windows have not been officially released yet, but you can download a build with those changes incorporated here.
(Source branch for that build can be found here).
Extract that file to the location of your choice. I chose C:\.
Configure Environment Variables
On Windows Storm requires the STORM_HOME and JAVA_HOME environment variables to be set, as well as some additions to the PATH variable:
JAVA_HOME
C:\Java\jdk1.7.0_45\
STORM_HOME
C:\storm-0.9.1-incubating-SNAPSHOT-12182013\
PATH Add:
%STORM_HOME%\bin;%JAVA_HOME%\bin;C:\Python27;C:\Python27\Lib\site-packages\;C:\Python27\Scripts\;
PATHEXT Add:
.PY
Start Nimbus, Supervisor, and Storm UI Daemons
For each deamon, open a separate command prompt.
Nimbus
> cd %STORM_HOME%
> storm nimbus
Supervisor
> cd %STORM_HOME%
> storm supervisor
Storm UI
> cd %STORM_HOME%
> storm ui
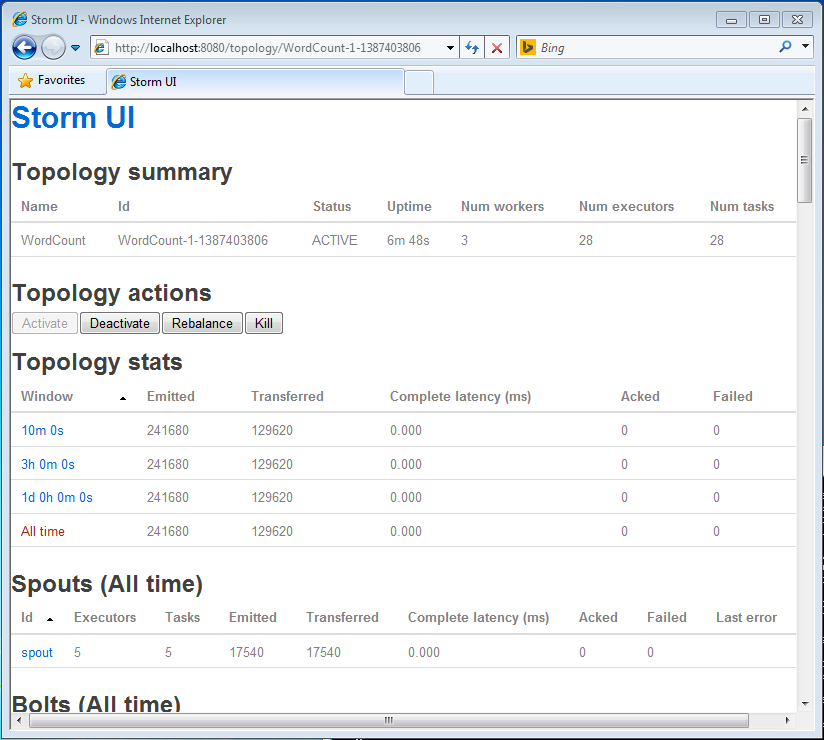
Verify that Storm is running by opening http://localhost:8080/ in a browser.
Deploy the “Word Count” Topology
Either build the storm-starter project from source, or download a pre-built jar
Deploy the Word Count topology to your local cluster with the storm jar command:
> storm jar storm-starter-0.0.1-SNAPSHOT-jar-with-dependencies.jar storm.starter.WordCountTopology WordCount -c nimbus.host=localhost
If you reload the Storm UI page, you should now see the “WordCount” topology listed and can click on the link to verify that the topology is processing data.
